
Develog
코드스테이츠 48-49일차 본문

학습 목표
- JPA가 무엇인지 이해할 수 있다.
- JPA의 동작방식을 이해할 수 있다.
- JPA API의 기본 사용방법을 이해할 수 있다.
- JPA 엔티티에 대한 매핑을 할 수 있다.
- JPA 기반의 엔티티 간 연관 관계를 매핑할 수 있다.
JPA(Java Persistence API)란?
JPA(Java Persistence API)는 Java 진영에서 사용하는 ORM(Object-Relational Mapping) 기술의 표준 사양(또는 명세, Specification)이다.
표준 사양(또는 명세)이라는 의미는 Java의 인터페이스로 사양이 정의되어 있기 때문에 JPA라는 표준 사양을 구현한 구현체는 따로 있다는 것을 의미한다.
Hibernate ORM
JPA 표준 사양을 구현한 구현체로는 Hibernate ORM, EclipseLink, DataNucleus 등이 있다.
Hibernate ORM은 JPA에서 정의해둔 인터페이스를 구현한 구현체로써 JPA에서 지원하는 기능 이외에 Hibernate 자체적으로 사용할 수 있는 API 역시 지원하고 있다.
JPA는 Java Persistence API의 약자이지만 현재는 Jakarta Persistence라고도 불린다.
데이터 액세스 계층에서의 JPA 위치

데이터 액세스 계층에서 JPA는 위의 그림과 같이 데이터 액세스 계층의 상단에 위치한다.
데이터 저장, 조회 등의 작업은 JPA를 거쳐 JPA의 구현체인 Hibernate ORM을 통해서 이루어지며 Hibernate ORM은 내부적으로 JDBC API를 이용해서 데이터베이스에 접근하게된다.
JPA(Java Persistence API)에서 P(Persistence)의 의미
Persistence는 영속성, 지속성이라는 뜻을 가지고 있다.
즉, 무언가를 금방 사라지지 않고 오래 지속되게 한다라는 것이 Persistence의 목적인 것이다.
영속성 컨텍스트(Persistence Context)
그렇다면 JPA에서는 도대체 무엇을 오래 지속하게 하는건데?
ORM은 객체(Object)와 데이터베이스 테이블의 매핑을 통해 엔티티 클래스 객체 안에 포함된 정보를 테이블에 저장하는 기술이다.
JPA에서는 테이블과 매핑되는 엔티티 객체 정보를 영속성 컨텍스트(Persistence Context)라는 곳에 보관해서 애플리케이션 내에서 오래 지속 되도록 한다.
그리고 이렇게 보관된 엔티티 정보는 데이터베이스 테이블에 데이터를 저장, 수정, 조회, 삭제하는데 사용된다.
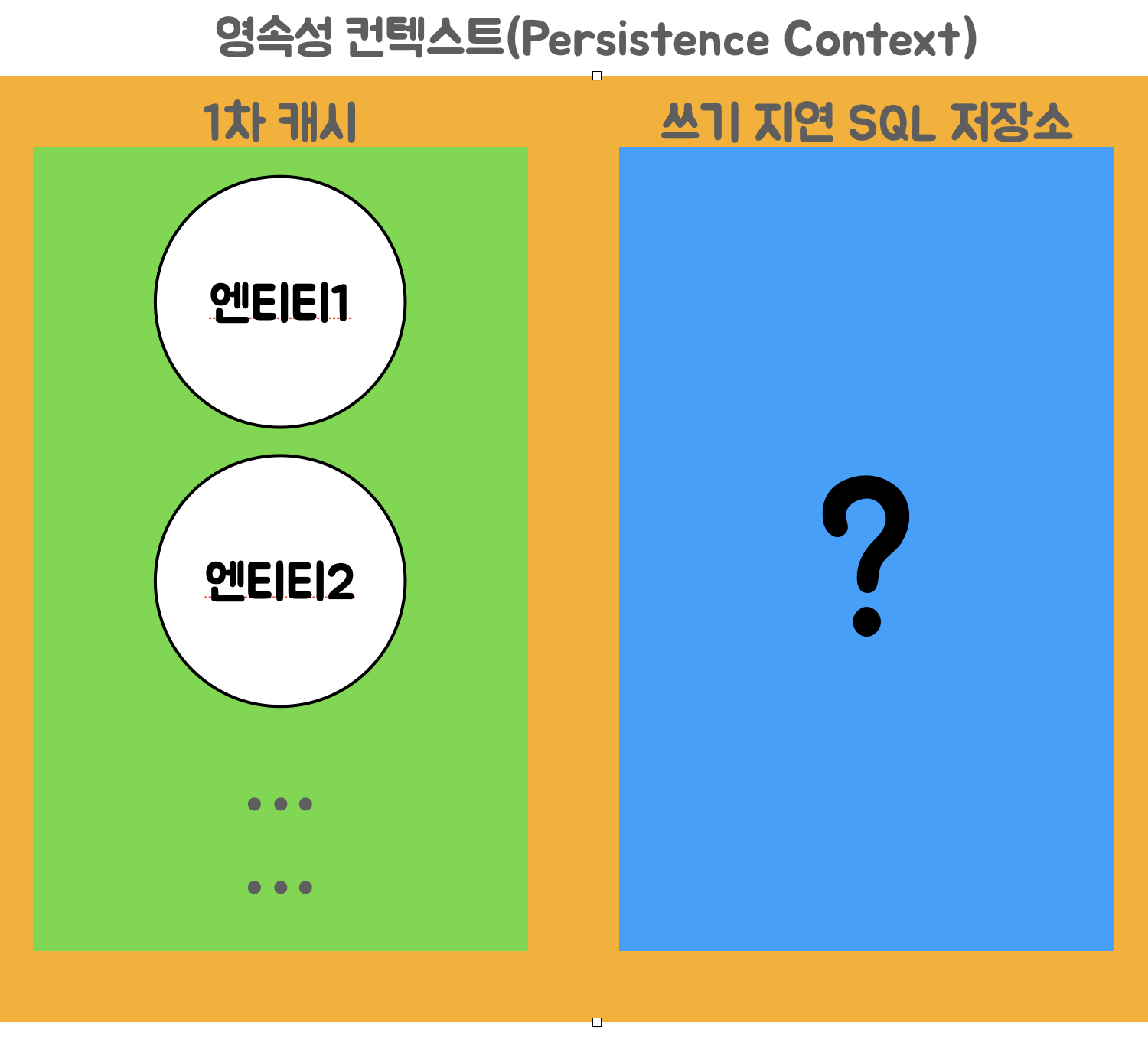
위의 그림과 같이 같이 영속성 컨텍스트에는 1차 캐시라는 영역과 쓰기 지연 SQL 저장소라는 영역이 있다.
JPA API 중에서 엔티티 정보를 영속성 컨텍스트에 저장(persist)하는 API를 사용하면 영속성 컨텍스트의 1차 캐시에 엔티티 정보가 저장된다.
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) { // (1)
this.em = emFactory.createEntityManager(); // (2)
return args -> {
Member member = new Member(“hyungjoon@gmail.com");
// (3)
em.persist(member);
// (4)
Member resultMember = em.find(Member.class, 1L);
System.out.println("Id: " + resultMember.getMemberId() + ", email: " +
resultMember.getEmail());
};
}
}- JPA의 영속성 컨텍스트는 EntityManager 클래스에 의해서 관리되는데 이 EntityManager 클래스의 객체는 (1)과 같이 EntityManagerFactory 객체를 Spring으로부터 DI 받을 수 있다.
- (2)와 같이 EntityManagerFactory의 createEntityManager() 메서드를 이용해서 EntityManager 클래스의 객체를 얻을 수 있다.
- 이제 이 EntityManager 클래스의 객체를 통해서 JPA의 API 메서드를 사용할 수 있다.
- (3)과 같이 persist(member) 메서드를 호출하면 영속성 컨텍스트에 member 객체의 정보들이 저장된다.
- (4)에서는 영속성 컨텍스트에 member 객체가 잘 저장되었는지 find(Member.class, 1L) 메서드로 조회하고 있다.
ㄴfind() 메서드의 파라미터 설명
ㄴ첫 번째 파라미터는 조회 할 엔티티 클래스의 타입이다.
ㄴ두 번째 파라미터는 조회 할 엔티티 클래스의 식별자 값이다.

em.persist(member)를 호출하면 위와같이 1차 캐시에 member 객체가 저장되고, 이 member 객체는 쓰기 지연 SQL 저장소에 INSERT 쿼리 형태로 등록이 된다.
위 코드의 출력 결과를 보면 ID가 1인 Member의 email 주소를 영속성 컨텍스트에서 조회하고 있는 것을 확인할 수 있다.
**Id: 1, email: hyungjoon@gmail.com**
member 객체 정보를 출력하는 라인 윗쪽 로그에서 JPA가 내부적으로 테이블을 자동 생성하고, 테이블의 기본키를 할당해주는 것을 확인할 수 있다.
그런데, em.persist(member) 를 호출할 경우, 영속성 컨텍스트에 member 객체를 저장하지만 실제 테이블에 회원 정보를 저장하지 않고 실제 로그에도 insert 쿼리가 확인되지 않는다.
✔ 영속성 컨텍스트와 테이블에 엔티티 저장
member 정보를 실제 테이블에 저장해보자
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
// (1)
this.tx = em.getTransaction();
return args -> {
// (2)
tx.begin();
Member member = new Member(“hyungjoon@gmail.com");
// (3)
em.persist(member);
// (4)
tx.commit();
// (5)
Member resultMember1 = em.find(Member.class, 1L);
System.out.println("Id: " + resultMember1.getMemberId() + ", email: " +
resultMember1.getEmail());
// (6)
Member resultMember2 = em.find(Member.class, 2L);
// (7)
System.out.println(resultMember2 == null);
};
}
}위와같은 코드를 통해 member 객체를 영속성 컨텍스트 뿐만 아니라 데이터베이스의 테이블에도 저장할 수 있다.
- (1)에서는 EntityManager를 통해서 Transaction 객체를 얻는다. JPA에서는 이 Transaction 객체를 기준으로 데이터베이스의 테이블에 데이터를 저장한다.
- JPA에서는 (2)와 같이 Transaction을 시작하기 위해서 tx.begin() 메서드를 먼저 호출해 주어야 한다.
- (3)에서 member 객체를 영속성 컨텍스트에 저장한다.
- (4)와 같이 tx.commit()을 호출하는 시점에 영속성 컨텍스트에 저장되어 있는 member 객체를 데이터베이스의 테이블에 저장한다.
- (5)에서 em.find(Member.class, 1L)을 호출하면 (3)에서 영속성 컨텍스트에 저장한 member 객체를 1차 캐시에서 조회한다.
1차 캐시에 member 객체 정보가 있기때문에 별도로 테이블에 SELECT 쿼리를 전송하지 않는다.
- (6)에서 em.find(Member.class, 2L)를 호출해서 식별자 값이 2L인 member 객체를 조회 합니다.
하지만 영속성 컨텍스트에는 식별자 값이 2L인 member 객체는 존재하지 않기 때문에 (7)의 결과는 true가 된다.
(6)에서는 영속성 컨텍스트에서 식별자 값이 2L인 member 객체가 존재하지 않기 때문에 테이블에 직접 SELECT 쿼리를 전송한다. (실행 결과 로그에서 확인가능)

tx.commit()을 했기 때문에 member에 대한 INSERT 쿼리는 실행되어 쓰기 지연 SQL 저장소에서 사라진다.
또한 실행 결과를 보면 SELECT 쿼리가 실행된 것을 볼 수 있다.
**Hibernate: select member0_.member_id as member_i1_0_0_,
member0_.email as email2_0_0_ from member member0_ where member0_.member_id=?**
이 SELECT 쿼리를 통해 em.find(Member.class, 2L)로 조회를 했는데 식별자 값이 2L에 해당하는 member2 객체가 영속성 컨텍스트의 1차 캐시에 없기 때문에 추가적으로 테이블에서 한번 더 조회한다는 것을 알 수 있다.
✅
위 두 개의 샘플 코드에서 기억해야할 포인트
- em.persist()를 호출하면 영속성 컨텍스트의 1차 캐시에 엔티티 클래스의 객체가 저장되고, 쓰기 지연 SQL 저장소에 INSERT 쿼리가 등록된다.
- tx.commit()을 하는 순간 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리가 실행되고, 실행된 INSERT 쿼리는 쓰기 지연 SQL 저장소에서 제거된다.
- em.find()를 호출하면 먼저 1차 캐시에서 해당 객체가 있는지 조회하고, 없으면 테이블에 SELECT 쿼리를 전송해서 조회한다.
✔ 영속성 컨텍스트와 테이블에 엔티티 업데이트
테이블에 이미 저장되어 있는 데이터를 JPA를 이용해서 어떻게 업데이트 할 수 있는지 살펴보자
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
tx.begin();
em.persist(new Member(“hyungjoon@gmail.com")); // (1)
tx.commit(); // (2)
tx.begin();
Member member1 = em.find(Member.class, 1L); // (3)
member1.setEmail(“ahnhyungjoon@yahoo.co.kr"); // (4)
tx.commit(); // (5)
};
}
}- 먼저 (1)에서 member 객체를 영속성 컨텍스트의 1차 캐시에 저장한다.
- (2)에서 tx.commit()을 호출해서 영속성 컨텍스트의 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리를 실행한다.
- (3)과 같이 (2)에서 테이블에 저장된 member 객체를 영속성 컨텍스트의 1차 캐시에서 조회한다.
테이블에서 조회하는 것이 아니다.
영속성 컨텍스트의 1차 캐시에 이미 저장된 객체가 있기때문에 영속성 컨텍스트에서 조회한다는 사실을 기억하자
- (4)에서 setter 메서드로 이메일 정보를 변경한다.
여기서 em.update() 같은 JPA API가 있을 것 같지만 (4)와 같이 setter 메서드로 값을 변경하기만 하면 업데이트 로직은 완성된 것이다.
- (5)에서 tx.commit()을 실행하면 쓰기 지연 SQL 저장소에 등록된 UPDATE 쿼리가 실행이 된다.
실행 결과를 보면 UPDATE 쿼리가 실행이 된 것을 확인할 수 있다.
**Hibernate: update member set email=? where member_id=?**
UPDATE 쿼리가 실행이 되는 과정
위와 같이 setter 메서드로 값을 변경만 해도 tx.commit() 시점에 UPDATE 쿼리가 실행이 되는 이유는 무엇일까?
영속성 컨텍스트에 엔티티가 저장될 경우에는 저장되는 시점의 상태를 그대로 가지고 있는 스냅샷을 생성한다.
그 후 해당 엔티티의 값을 setter 메서드로 변경한 후, tx.commit()을 하면 변경된 엔티티와 이 전에 이미 떠 놓은 스냅샷을 비교한 후, 변경된 값이 있으면 쓰기 >지연 SQL 저장소에 UPDATE 쿼리를 등록하고 UPDATE 쿼리를 실행한다.
✔ 영속성 컨텍스트와 테이블의 엔티티 삭제
@Configuration
public class JpaBasicConfig {
private EntityManager em;
private EntityTransaction tx;
@Bean
public CommandLineRunner testJpaBasicRunner(EntityManagerFactory emFactory) {
this.em = emFactory.createEntityManager();
this.tx = em.getTransaction();
return args -> {
tx.begin();
em.persist(new Member("hgd1@gmail.com")); // (1)
tx.commit(); //(2)
tx.begin();
Member member = em.find(Member.class, 1L); // (3)
em.remove(member); // (4)
tx.commit(); // (5)
};
}
}- 먼저 (1)에서 Member 클래스의 객체를 영속성 컨텍스트의 1차 캐시에 저장한다.
- (2)에서 tx.commit()을 호출해서 영속성 컨텍스트의 쓰기 지연 SQL 저장소에 등록된 INSERT 쿼리를 실행한다.
- (2)에서 테이블에 저장된 Member 클래스의 객체를 (3)과 같이 영속성 컨텍스트의 1차 캐시에서 조회한다.
- (4)에서 em.remove(member)을 통해 영속성 컨텍스트의 1차 캐시에 있는 엔티티를 제거를 요청한다.
- (5)에서 tx.commit()을 실행하면 영속성 컨텍스트의 1차 캐시에 있는 엔티티를 제거하고, 쓰기 지연 SQL 저장소에 등록된 DELETE 쿼리가 실행이 된다.
EntityManager의 flush() API
tx.commit() 메서드가 호출되면 JPA 내부적으로 em.flush() 메서드가 호출되어 영속성 컨텍스트의 변경 내용을 데이터베이스에 반영한다는 사실을 알아두자
총정리
- JPA(Java Persistence API)는 Java 진영에서 사용하는 ORM(Object-Relational Mapping) 기술의 표준 사양(또는 명세, Specification)이다.
- Hibernate ORM은 JPA에서 정의해둔 인터페이스를 구현한 구현체로써 JPA에서 지원하는 기능 이외에 Hibernate 자체적으로 사용할 수 있는 API 역시 지원하고있다.
- JPA에서는 테이블과 매핑되는 엔티티 객체 정보를 영속성 컨텍스트(Persistence Context)에 보관해서 애플리케이션 내에서 오래 지속 되도록 한다.
- 영속성 컨텍스트 관련 JPA API
ㄴem.persist()를 사용해서 엔티티 객체를 영속성 컨텍스트에 저장할 수 있다.
ㄴ엔티티 객체의 setter 메서드를 사용해서 영속성 컨텍스트에 저장된 엔티티 객체의 정보를 업데이트 할 수 있다.
ㄴem.remove()를 사용해서 엔티티 객체를 영속성 컨텍스트에서 제거할 수 있다.
ㄴem.flush()를 사용해서 영속성 컨텍스트의 변경 사항을 테이블에 반영할 수 있다.
ㄴtx.commit()을 호출하면 내부적으로 em.flush()가 호출된다.
엔티티 매핑
JPA를 이용해 데이터베이스의 테이블과 상호 작용(데이터 저장, 수정, 조회, 삭제 등) 하기 위해 제일 먼저 해야되는 작업은 바로 데이터베이스의 테이블과 엔티티 클래스 간의 매핑 작업이다.
엔티티 매핑 작업은 크게 객체와 테이블 간의 매핑, 기본키 매핑, 필드(멤버 변수)와 컬럼 간의 매핑, 엔티티 간의 연관 관계 매핑 등으로 나눌 수 있다.
엔티티와 테이블 간의 매핑
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
@Table
public class Member {
@Id
private Long memberId;
}@Entity 매핑 애너테이션을 이용해 엔티티 클래스와 테이블을 매핑
클래스 레벨에 @Entity 애너테이션을 붙이면 JPA 관리 대상 엔티티가 된다.
✔ @Entity 애너테이션 설명
애트리뷰트
- name
ㄴ엔티티 이름을 설정할 수 있다.
ㄴname 애트리뷰트를 설정하지 않으면 기본값으로 클래스 이름을 엔티티 이름으로 사용한다.
아래와 같이 name 애트리뷰트를 사용해서 엔티티 이름과 테이블 이름을 변경할 수 있다.
@Entity(name = "USERS") // (1)
@Table(name = "USERS") // (2)
public class Member {
@Id
private Long memberId;
}✔ @Table 애너테이션 설명
애트리뷰트
- name
ㄴ테이블 이름을 설정할 수 있다.
ㄴname 애트리뷰트를 설정하지 않으면 기본값으로 클래스 이름을 테이블 이름으로 사용한다.
ㄴ@Table 애너테이션은 옵션이며, 추가하지 않을 경우 클래스 이름을 테이블 이름으로 사용한다.
ㄴ주로 테이블 이름이 클래스 이름과 달라야 할 경우에 추가한다.
✅ 주의 사항
- @Table 애너테이션은 옵션이지만 @Entity 애너테이션과 @Id 애너테이션은 필수이다.
- @Entity 애너테이션과 @Id 애너테이션은 함께 사용하자
ㄴ만약에 @Entity 애너테이션만 추가하고 식별자 역할을 하는 필드(멤버 변수)에 @Id 애너테이션을 추가하지 않으면 다음과 같은 에러가 발생한다.
ㄴCaused by: org.hibernate.AnnotationException: No identifier specified for entity: com.codestates.entity_mapping.single_mapping.Member
- 파라미터가 없는 기본 생성자는 필수로 추가해주세요.
ㄴSpring Data JPA의 기술을 적용할 때 기본 생성자가 없는 경우 에러가 발생하는 경우가 있기때문에 기본 생성자는 습관적으로 추가하는 것이 좋다.
- 중복되는 엔티티 클래스가 없고, 테이블 이름이 클래스 이름과 같을 경우에는 @Entity 애너테이션과 @Table 애너테이션에 name 애트리뷰트를 지정하지 않고, 클래스 이름으로 사용하는게 권장된다.
기본키 매핑
데이터베이스의 테이블에 기본키 설정은 필수라고 할 수 있다.
JPA에서는 기본적으로 @Id 애너테이션을 추가한 필드가 기본 키 컬럼이 되는데, JPA에서는 이러한 기본 키를 어떤 방식으로 생성해 줄지에 대한 다양한 전략을 지원한다.
기본키 직접 할당
- 애플리케이션 코드 상에서 기본키를 직접 할당 해주는 방식이다.
기본키 자동 생성
- IDENTITY
ㄴ기본키 생성을 데이터베이스에 위임하는 전략이다.
ㄴ데이터베이스에서 기본키를 생성해주는 대표적인 방식은 MySQL의 AUTO_INCREMENT 기능을 통해 자동 증가 숫자를 기본키로 사용하는 방식이 있다.
- SEQUENCE
ㄴ데이터베이스에서 제공하는 시퀀스를 사용해서 기본키를 생성하는 전략이다.
- TABLE
ㄴ별도의 키 생성 테이블을 사용하는 전략이다.
✔ 기본키 직접 할당 전략
단순히 @Id 애너테이션만 추가하면 기본적으로 기본키 직접 할당 전략이 적용된다.
만약 기본키 없이 엔티티를 저장하면 아래와 같은 에러 메시지를 출력한다.
Caused by: javax.persistence.PersistenceException: org.hibernate.id.IdentifierGenerationException: ids for this class must be manually assigned before calling save(): … …
✔ IDENTITY 전략
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // (1)
private Long memberId;
public Member(Long memberId) {
this.memberId = memberId;
}
}IDENTITY 기본키 생성 전략을 설정하려면 위와같이 @GeneratedValue 애너테이션의 strategy 애트리뷰트의 값을 GenerationType.IDENTITY로 지정해주면 된다.
✔ SEQUENCE 전략
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE) // (1)
private Long memberId;
public Member(Long memberId) {
this.memberId = memberId;
}
}SEQUENCE 전략을 사용하기 위해서는 @GeneratedValue(strategy = GenerationType.SEQUENCE)를 지정하면 된다.
✔ AUTO 전략
@Id 필드에 @GeneratedValue(strategy = GenerationType.AUTO)를 지정하면 JPA가 데이터베이스의 Dialect에 따라서 적절한 전략을 자동으로 선택한다.
필드(멤버 변수)와 컬럼 간의 매핑
Member 엔티티 클래스 필드와 컬럼 간의 매핑
@NoArgsConstructor
@Getter
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long memberId;
// (1)
@Column(nullable = false, updatable = false, unique = true)
private String email;
...
...
public Member(String email) {
this.email = email;
}
}(1)에서 사용한 @Column 애너테이션은 필드와 컬럼을 매핑해주는 애너테이션이다. 그런데 만약 @Column 애너테이션이 없고, 필드만 정의되어 있다면 JPA는 기본적으로 이 필드가 테이블의 컬럼과 매핑되는 필드라고 간주하게된다. 또한, @Column 애너테이션에 사용되는 애트리뷰트의 값은 디폴트 값이 모두 적용된다.
애트리뷰트
- nullable
ㄴ컬럼에 null 값을 허용할지 여부를 지정한다.
ㄴ디폴트 값은 true이다.
- updatable
ㄴ컬럼 데이터를 수정할 수 있는지 여부를 지정한다.
ㄴ디폴트 값은 true이다.
- unique
ㄴ하나의 컬럼에 unique 유니크 제약 조건을 설정한다.
ㄴ디폴트 값은 false이다.
✅ @Column 애너테이션이 생략되었거나 애트리뷰트가 기본값을 사용할 경우 주의 사항
@Column 애너테이션이 생략된 경우 기본적으로 nullable=true이다.
그런데 필드의 데이터 타입이 int, long 같은 Java의 원시 타입이라면 null 값을 입력할 수 없다.
따라서 만약 Java의 원시 타입 필드에서 @Column 애너테이션이 없거나 @Column 애너테이션이 있지만 애트리뷰트를 생략한 경우, 최소한 nullable=false는 설정하는 것이 에러를 미연에 방지할 수 있다는 점을 기억하자
엔티티 클래스에서 발생한 예외는 API 계층까지 전파되므로 API 계층의 GlobalExceptionAdvice 에서 캐치(catch)한 후, 처리할 수 있다.
// (1)
@Column(length = 100, nullable = false)
private String name;
@Column(length = 13, nullable = false, unique = true)
private String phone;
// (2)
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now();
// (3)
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
// (4)
@Transient
private String age;(1)의 @Column 애너테이션
- 애트리뷰트
ㄴlength
ㄴ컬럼에 저장할 수 있는 문자 길이를 지정할 수 있다.
ㄴ디폴트 값은 255이다.
(2)는 회원 정보가 등록 될 때의 시간 및 날짜를 매핑하기 위한 필드이다.
ㄴjava.util.Date, java.util.Calendar 타입으로 매핑하기 위해서는 @Temporal 애너테이션을 추가해야하지만 (2)와 같이 LocalDateTime 타입일 경우, @Temporal 애너테이션은 생략 가능하다.
ㄴLocalDateTime은 컬럼의 TIMESTAMP 타입과 매핑된다.
@Column 애너테이션의 name 애트리뷰트를 생략하면 엔티티 클래스 필드의 이름으로 컬럼이 생성되지만 (3)과 같이 name 애트리뷰트에 별도의 이름을 지정해서 엔티티 클래스 필드명과 다른 이름으로 컬럼을 생성할 수 있다.
(4)와 같이 @Transient 애너테이션을 필드에 추가하면 테이블 컬럼과 매핑하지 않겠다는 의미로 JPA가 인식한다.
ㄴ따라서 데이터베이스에 저장도 하지 않고, 조회할 때 역시 매핑되지 않는다.
ㄴ@Transient은 주로 임시 데이터를 메모리에서 사용하기위한 용도로 사용된다.
// (1)
@Enumerated(EnumType.STRING)
private OrderStatus orderStatus = OrderStatus.ORDER_REQUEST;
@Column(nullable = false)
private LocalDateTime createdAt = LocalDateTime.now();
@Column(nullable = false, name = "LAST_MODIFIED_AT")
private LocalDateTime modifiedAt = LocalDateTime.now();
public enum OrderStatus {
ORDER_REQUEST(1, "주문 요청"),
ORDER_CONFIRM(2, "주문 확정"),
ORDER_COMPLETE(3, "주문 완료"),
ORDER_CANCEL(4, "주문 취소");- (1)의 @Enumerated 애너테이션은 enum 타입과 매핑할 때 사용하는 애너테이션이다.
ㄴ@Enumerated 애너테이션은 아래의 두 가지 타입을 가질 수 있다.
ㄴEnumType.ORDINAL : enum의 순서를 나타내는 숫자를 테이블에 저장한다.
ㄴEnumType.STRING : enum의 이름을 테이블에 저장한다.
ㄴ✅ 주의
ㄴEnumType.ORDINAL 로 지정할 경우, 기존에 정의되어 있는 enum 사이에 새로운 enum 하나가 추가 된다면 그때부터 테이블에 이미 저장되어 있는 enum 순서 번호와 enum에 정의되어 있는 순서가 일치하지 않게 되는 문제가 발생한다.
ㄴ따라서 처음부터 이런 문제가 발생하지 않도록 EnumType.STRING 을 사용하는 것을 권장하고 있다.
엔티티와 테이블 매핑 권장 사용 방법
- 클래스 이름 중복 등의 특별한 이유가 없다면 @Entity와 @Id 애너테이션만 추가한다.
ㄴ만일 엔티티 클래스가 테이블 스키마 명세의 역할을 하길 바란다면 @Table 애너테이션에 테이블명을 지정해줄 수 있다.
- 기본키 생성 전략은 데이터베이스에서 지원해주는 AUTO_INCREMENT 또는 SEQUENCE를 이용할 수 있도록 IDENTITY 또는 SEQUENCE 전략을 사용하는 것이 좋다.
- @Column 정보를 명시적으로 모두 지정하는 것은 번거롭긴하지만 다른 누군가가 엔티티 클래스 코드를 확인하더라도 테이블 설계가 어떤식으로 되어 있는지 한눈에 알 수 있다는 장점이 있다.
- 엔티티 클래스 필드 타입이 Java의 원시타입일 경우, @Column 애너테이션을 생략하지 말고, 최소한 nullable=false 설정을 하는게 좋다.
- @Enumerated 애너테이션을 사용할 때 EnumType.ORDINAL 을 사용할 경우, enum의 순서가 뒤바뀔 가능성도 있으므로 처음부터 EnumType.ORDINAL 대신에 EnumType.STRING 을 사용하는 것이 좋다.
총정리
- @Entity 애너테이션을 클래스 레벨에 추가하면 JPA의 관리대상 엔티티가 된다.
- @Table 애너테이션은 엔티티와 매핑할 테이블을 지정한다.
- @Entity 애너테이션과 @Id 애너테이션은 필수로 추가해야 한다.
- JPA는 IDENTITY, SEQUENCE, TABLE, AUTO 전략 같은 다양한 기본키 생성 전략을 지원한다.
ㄴIDENTITY 전략
ㄴ기본키 생성을 데이터베이스에 위임하는 전략이다.
ㄴSEQUENCE 전략
ㄴ데이터베이스에서 제공하는 시퀀스를 사용해서 기본키를 생성하는 전략이다.
ㄴTABLE 전략
ㄴ별도의 키 생성 테이블을 사용하는 전략이다.
ㄴAUTO 전략
ㄴJPA가 데이터베이스의 Dialect에 따라서 적절한 전략을 자동으로 선택한다.
- Java의 원시 타입 필드에서 @Column 애너테이션이 없거나 @Column 애너테이션이 있지만 애트리뷰트를 생략한 경우, 최소한 nullable=false는 설정하는 것이 에러를 미연에 방지하는 길이다.
- java.util.Date, java.util.Calendar 타입으로 매핑하기 위해서는 @Temporal 애너테이션을 추가해야하지만 LocalDate, LocalDateTime 타입일 경우, @Temporal 애너테이션은 생략 가능하다.
- @Transient 애너테이션을 필드에 추가하면 JPA가 테이블 컬럼과 매핑하지 않겠다는 의미로 인식한다.
- 테이블에 이미 저장되어 있는 enum 순서 번호와 enum에 정의되어 있는 순서가 일치하지 않게 되는 문제가 발생하지 않도록 EnumType.STRING 을 사용하는 것이 좋다.
'코드스테이츠' 카테고리의 다른 글
| 코드스테이츠 51일차 (0) | 2022.07.07 |
|---|---|
| 코드스테이츠 50일차 (0) | 2022.07.06 |
| 코드스테이츠 47일차 (0) | 2022.07.03 |
| 코드스테이츠 46일차 (0) | 2022.06.30 |
| 코드스테이츠 45일차 (0) | 2022.06.29 |



